Publications
2025
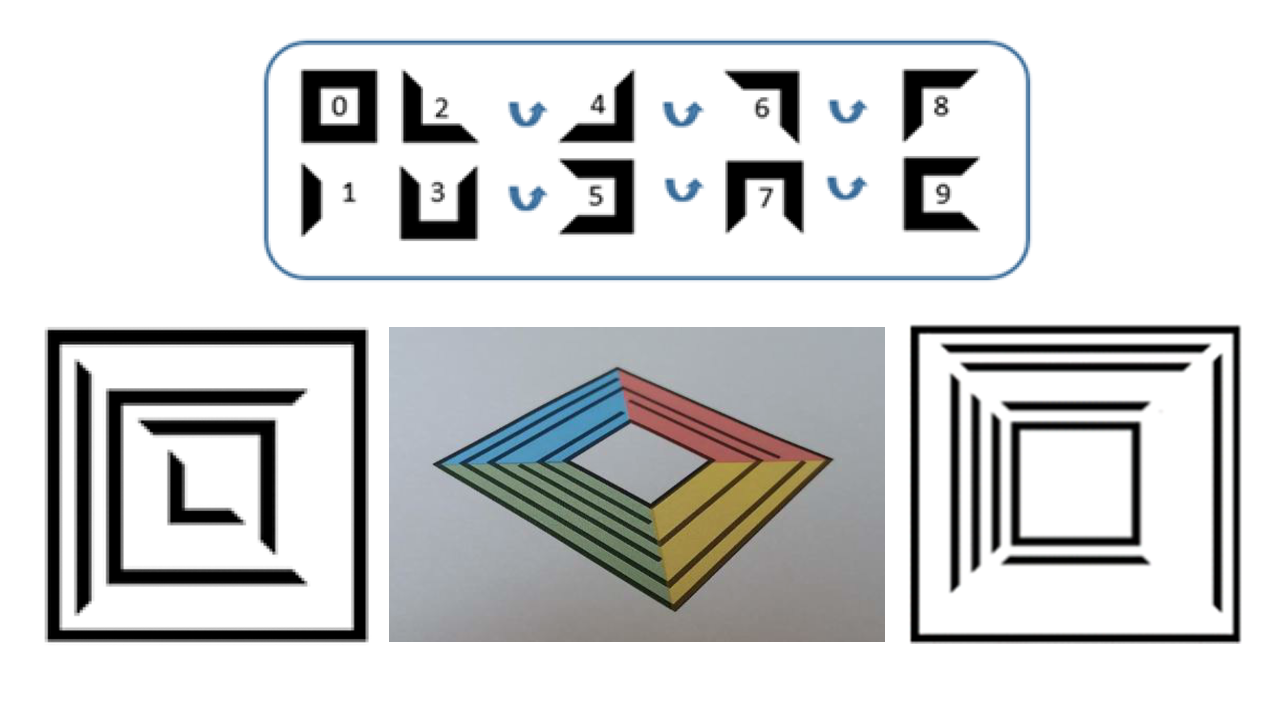
Efficient Line-Based Visual Marker System Design with Occlusion Resilience
Abdallah Bengueddoudj, Foudil Belhadj, Yongtao Hu, Brahim Zitouni, Yacine Idir, Ibtissem Adoui, and Messaoud Mostefai
Informatica (Informatica 2025)
"novel pyramidal line-based fiducial marker system that humans can read and offers enhanced performance"
Abdallah Bengueddoudj, Foudil Belhadj, Yongtao Hu, Brahim Zitouni, Yacine Idir, Ibtissem Adoui, and Messaoud Mostefai
Informatica (Informatica 2025)
"novel pyramidal line-based fiducial marker system that humans can read and offers enhanced performance"
- project page
- paper
-
abstract
Today, the most widely used visual markers, such as ArUco and AprilTag, rely on square pixel arrays. While these markers can deliver satisfactory detection and identification outcomes, they remain vulnerable to corner occlusion despite incorporating corrective codes. Conversely, line-based markers offer increased resilience against occlusions but are typically constrained in terms of codification capacities. The markers developed in this research leverage linear information to propose a pyramidal line-based structure that exhibits robustness to corner occlusion while providing enhanced coding capacities. Moreover, the projective invariance of the constituent lines enables the validation of a homography-less identification method that considerably reduces computation resources and processing time. We assembled an extensive test dataset of 169,713 images for evaluation, including rotation, distances, and different levels of occlusion. Experiments on this dataset show that the proposed marker significantly outperforms previous fiducial marker systems across multiple metrics, including execution time and detection performance under occlusion. It effectively identifies markers with up to 50% occlusion and achieves identification at a resolution of 1920x1080 in 17.20 ms. The developed marker generation and identification, as well as an extensive marker Database, are publicly available for tests at https://github.com/OILUproject/OILUtag
-
bibtex
@article{Bengueddoudj2025oilutag, title={{Efficient Line-Based Visual Marker System Design with Occlusion Resilience}}, author={Bengueddoudj, Abdallah and Belhadj, Foudil and Hu, Yongtao and Zitouni, Brahim and Idir, Yacine and Adoui, Ibtissem and Mostefai, Messaoud}, journal={Informatica}, volume={49}, number={1}, pages={61-80}, year={2025}, publisher={} } - DOI
2023
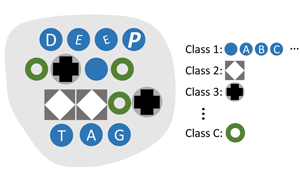
DeepTag: A General Framework for Fiducial Marker Design and Detection
Zhuming Zhang, Yongtao Hu, Guoxing Yu, and Jingwen Dai
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2023)
"the 1st general framework for fiducial marker system, support both existing markers and newly-designed ones"
Zhuming Zhang, Yongtao Hu, Guoxing Yu, and Jingwen Dai
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2023)
"the 1st general framework for fiducial marker system, support both existing markers and newly-designed ones"
- project page
- preprint (arXiv)
-
abstract
A fiducial marker system usually consists of markers, a detection algorithm, and a coding system. The appearance of markers and the detection robustness are generally limited by the existing detection algorithms, which are hand-crafted with traditional low-level image processing techniques. Furthermore, a sophisticatedly designed coding system is required to overcome the shortcomings of both markers and detection algorithms. To improve the flexibility and robustness in various applications, we propose a general deep learning based framework, DeepTag, for fiducial marker design and detection. DeepTag not only supports detection of a wide variety of existing marker families, but also makes it possible to design new marker families with customized local patterns. Moreover, we propose an effective procedure to synthesize training data on the fly without manual annotations. Thus, DeepTag can easily adapt to existing and newly-designed marker families. To validate DeepTag and existing methods, beside existing datasets, we further collect a new large and challenging dataset where markers are placed in different view distances and angles. Experiments show that DeepTag well supports different marker families and greatly outperforms the existing methods in terms of both detection robustness and pose accuracy. Both code and dataset are available.
- source code
- dataset
-
bibtex
@article{zhang2023deeptag, title={{DeepTag: A General Framework for Fiducial Marker Design and Detection}}, author={Zhang, Zhuming and Hu, Yongtao and Yu, Guoxing and Dai, Jingwen}, journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, volume={45}, number={3}, pages={2931-2944}, year={2023}, publisher={IEEE} } - DOI
2021

TopoTag: A Robust and Scalable Topological Fiducial Marker System
Guoxing Yu, Yongtao Hu, and Jingwen Dai
IEEE Transactions on Visualization and Computer Graphics (TVCG 2021)
"novel fiducial marker system with much improved detection & pose accuracy, scalability and shape flexibility"
Guoxing Yu, Yongtao Hu, and Jingwen Dai
IEEE Transactions on Visualization and Computer Graphics (TVCG 2021)
"novel fiducial marker system with much improved detection & pose accuracy, scalability and shape flexibility"
- project page
- preprint (arXiv)
- supplemental material
-
abstract
Fiducial markers have been playing an important role in augmented reality (AR), robot navigation, and general applications where the relative pose between a camera and an object is required. Here we introduce TopoTag, a robust and scalable topological fiducial marker system, which supports reliable and accurate pose estimation from a single image. TopoTag uses topological and geometrical information in marker detection to achieve higher robustness. Topological information is extensively used for 2D marker detection, and further corresponding geometrical information for ID decoding. Robust 3D pose estimation is achieved by taking advantage of all TopoTag vertices. Without sacrificing bits for higher recall and precision like previous systems, TopoTag can use full bits for ID encoding. TopoTag supports tens of thousands unique IDs and easily extends to millions of unique tags resulting in massive scalability. We collected a large test dataset including in total 169,713 images for evaluation, involving in-plane and out-of-plane rotation, image blur, different distances and various backgrounds, etc. Experiments on the dataset and real indoor and outdoor scene tests with a rolling shutter camera both show that TopoTag significantly outperforms previous fiducial marker systems in terms of various metrics, including detection accuracy, vertex jitter, pose jitter and accuracy, etc. In addition, TopoTag supports occlusion as long as the main tag topological structure is maintained and allows for flexible shape design where users can customize internal and external marker shapes. Code for our marker design/generation, marker detection, and dataset are available at https://herohuyongtao.github.io/research/publications/topo-tag/.
- source code
- dataset
-
bibtex
@article{yu2021topotag, title={{TopoTag: A Robust and Scalable Topological Fiducial Marker System}}, author={Yu, Guoxing and Hu, Yongtao and Dai, Jingwen}, journal={IEEE Transactions on Visualization and Computer Graphics (TVCG)}, volume={27}, number={9}, pages={3769-3780}, year={2021}, publisher={IEEE} } - DOI
2019
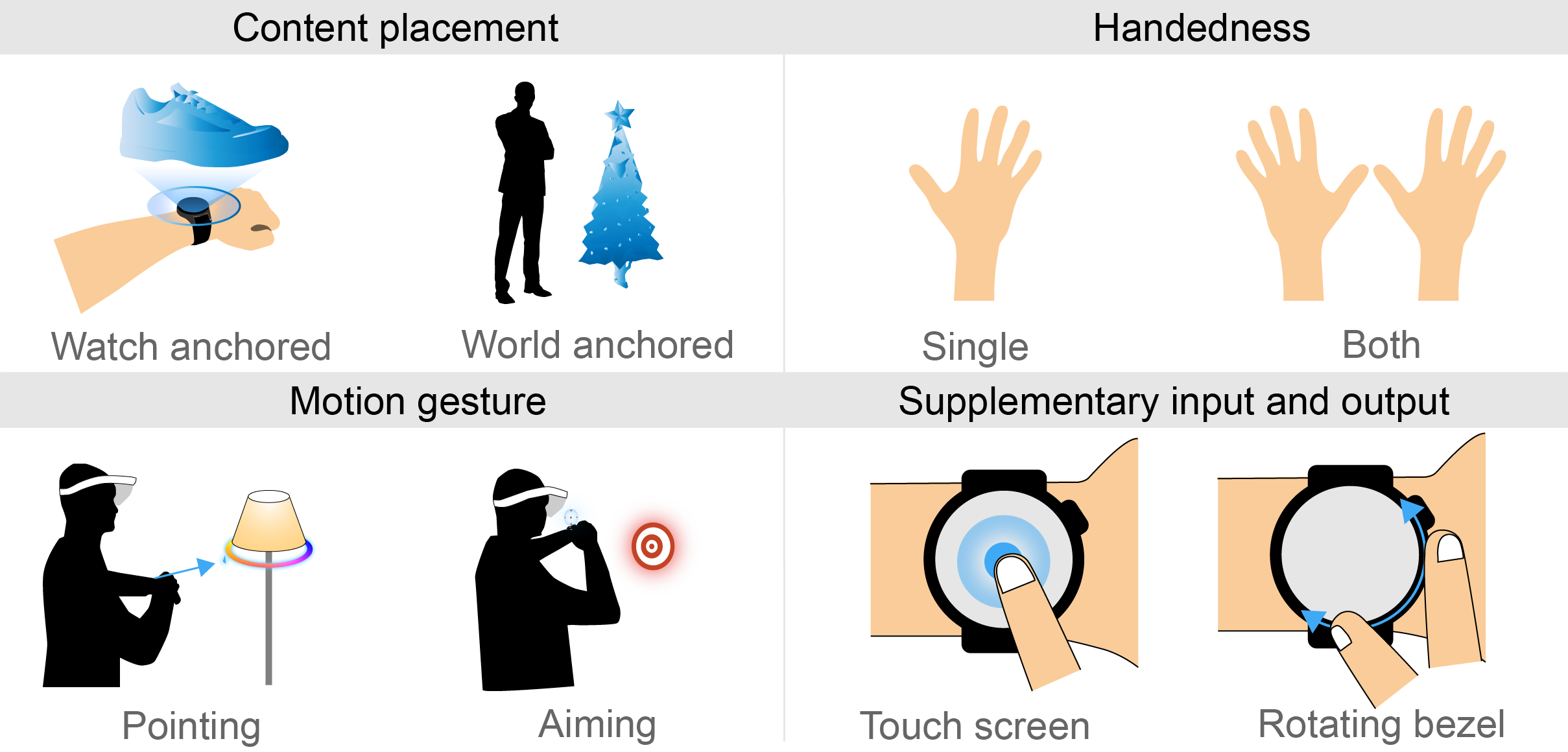
WatchAR: 6-DoF Tracked Watch for AR Interaction
Zhixiong Lu, Yongtao Hu, and Jingwen Dai
2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR 2019, demo)
"6-DoF trackable watch with novel AR interactions"
Zhixiong Lu, Yongtao Hu, and Jingwen Dai
2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR 2019, demo)
"6-DoF trackable watch with novel AR interactions"
- project page
- paper
-
abstract
AR is about to change how people observe and interact with the world. Smart wearable devices are widely used, their input interfaces, like button, rotating bezel, and inertial sensors are good supplementary for interaction. Further 6-DoF information of these wearables will provide richer interaction modalities. We present WatchAR, an interaction system of 6-DoF trackable smartwatch for mobile AR. Three demos demonstrate different interactions: Air Hit shows a way to acquire 2D target with single hand; Picker Input shows how to select an item from a list efficiently; Space Fighter demonstrates the potential of WatchAR for interacting with a game.
-
bibtex
@inproceedings{lu2019watchar, title={{WatchAR: 6-DoF Tracked Watch for AR Interaction}}, author={Lu, Zhixiong and Hu, Yongtao and Dai, Jingwen}, booktitle={2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR, demo)}, pages={}, year={2019}, organization={IEEE} }
2017
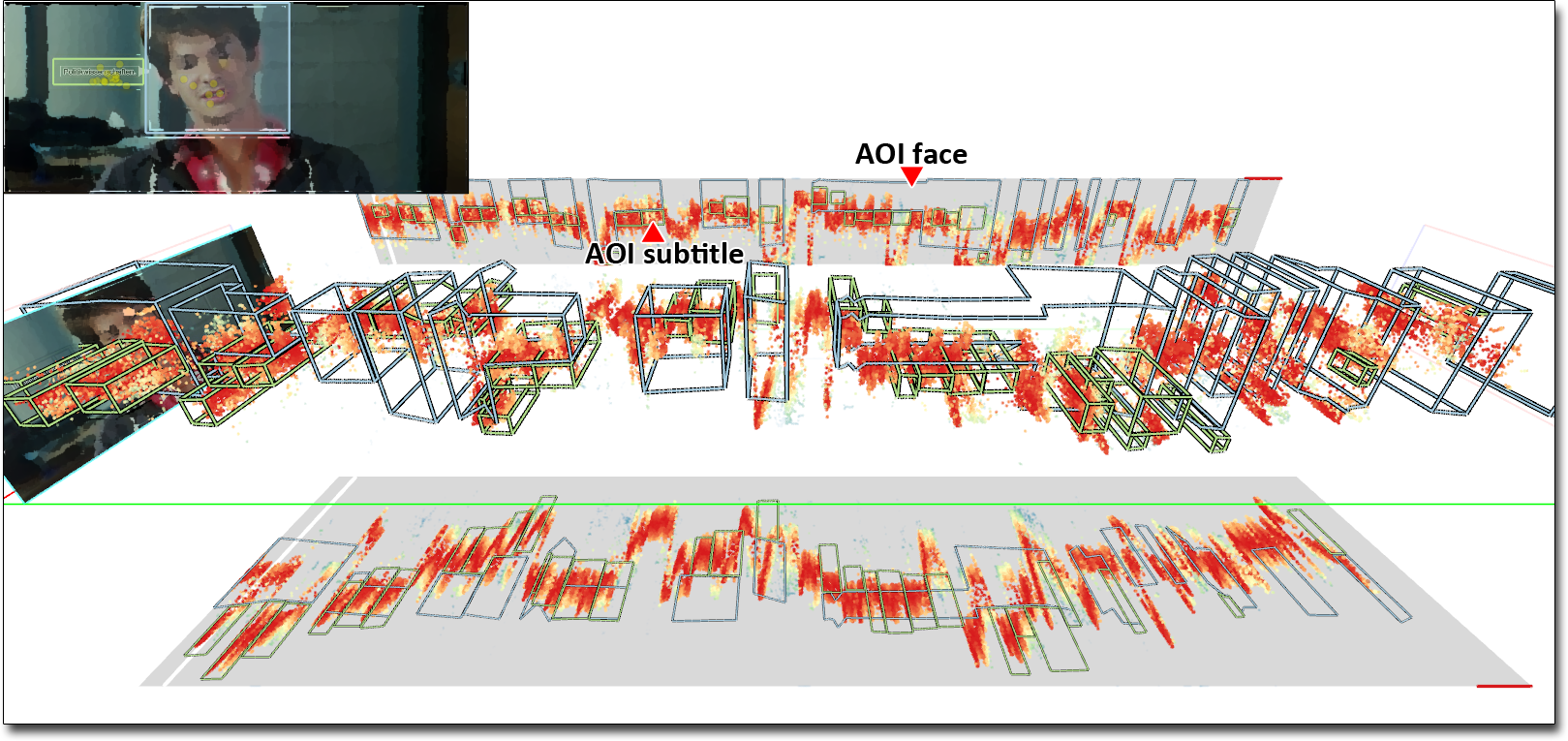
Close to the Action: Eye-Tracking Evaluation of Speaker-Following Subtitles
Kuno Kurzhals, Emine Cetinkaya, Yongtao Hu, Wenping Wang, and Daniel Weiskopf
The 35th ACM Conference on Human Factors in Computing Systems (CHI 2017)
"eye-tracking evaluation of speaker-following subtitles"
Kuno Kurzhals, Emine Cetinkaya, Yongtao Hu, Wenping Wang, and Daniel Weiskopf
The 35th ACM Conference on Human Factors in Computing Systems (CHI 2017)
"eye-tracking evaluation of speaker-following subtitles"
- project page
- paper
-
abstract
The incorporation of subtitles in multimedia content plays an important role in communicating spoken content. For example, subtitles in the respective language are often preferred to expensive audio translation of foreign movies. The traditional representation of subtitles displays text centered at the bottom of the screen. This layout can lead to large distances between text and relevant image content, causing eye strain and even that we miss visual content. As a recent alternative, the technique of speaker-following subtitles places subtitle text in speech bubbles close to the current speaker. We conducted a controlled eye-tracking laboratory study (n = 40) to compare the regular approach (center-bottom subtitles) with content-sensitive, speaker-following subtitles. We compared different dialog-heavy video clips with the two layouts. Our results show that speaker-following subtitles lead to higher fixation counts on relevant image regions and reduce saccade length, which is an important factor for eye strain.
-
bibtex
@inproceedings{kurzhals2017close, title={{Close to the Action: Eye-Tracking Evaluation of Speaker-Following Subtitles}}, author={Kurzhals, Kuno and Cetinkaya, Emine and Hu, Yongtao and Wang, Wenping and Weiskopf, Daniel}, booktitle={Proceedings of the 35th ACM Conference on Human Factors in Computing Systems}, pages={6559--6568}, year={2017}, organization={ACM} } - DOI
2016

Look, Listen and Learn - A Multimodal LSTM for Speaker Identification
Jimmy SJ. Ren, Yongtao Hu, Yu-Wing Tai, Chuan Wang, Li Xu, Wenxiu Sun, and Qiong Yan
The 30th AAAI Conference on Artificial Intelligence (AAAI 2016, oral)
"speaker identification through multimodal weight sharing LSTM"
Jimmy SJ. Ren, Yongtao Hu, Yu-Wing Tai, Chuan Wang, Li Xu, Wenxiu Sun, and Qiong Yan
The 30th AAAI Conference on Artificial Intelligence (AAAI 2016, oral)
"speaker identification through multimodal weight sharing LSTM"
- project page
- paper
-
abstract
Speaker identification refers to the task of localizing the face of a person who has the same identity as the ongoing voice in a video. This task not only requires collective perception over both visual and auditory signals, the robustness to handle severe quality degradations and unconstrained content variations are also indispensable. In this paper, we describe a novel multimodal Long Short-Term Memory (LSTM) architecture which seamlessly unifies both visual and auditory modalities from the beginning of each sequence input. The key idea is to extend the conventional LSTM by not only sharing weights across time steps, but also sharing weights across modalities. We show that modeling the temporal dependency across face and voice can significantly improve the robustness to content quality degradations and variations. We also found that our multimodal LSTM is robustness to distractors, namely the non-speaking identities. We applied our multimodal LSTM to The Big Bang Theory dataset and showed that our system outperforms the state-of-the-art systems in speaker identification with lower false alarm rate and higher recognition accuracy.
- source code & dataset
- more applications
-
bibtex
@inproceedings{ren2016look, title={{Look, Listen and Learn - A Multimodal LSTM for Speaker Identification}}, author={Ren, Jimmy SJ. and Hu, Yongtao and Tai, Yu-Wing and Wang, Chuan and Xu, Li and Sun, Wenxiu and Yan, Qiong}, booktitle={Proceedings of the 30th AAAI Conference on Artificial Intelligence}, pages={3581--3587}, year={2016} } - DOI
2015

Deep Multimodal Speaker Naming
Yongtao Hu, Jimmy SJ. Ren, Jingwen Dai, Chang Yuan, Li Xu, and Wenping Wang
The 23rd Annual ACM International Conference on Multimedia (MM 2015)
"realtime speaker naming through CNN based deeply learned face-audio fusion"
Yongtao Hu, Jimmy SJ. Ren, Jingwen Dai, Chang Yuan, Li Xu, and Wenping Wang
The 23rd Annual ACM International Conference on Multimedia (MM 2015)
"realtime speaker naming through CNN based deeply learned face-audio fusion"
- project page
- paper
- poster
-
abstract
Automatic speaker naming is the problem of localizing as well as identifying each speaking character in a TV/movie/live show video. This is a challenging problem mainly attributes to its multimodal nature, namely face cue alone is insufficient to achieve good performance. Previous multimodal approaches to this problem usually process the data of different modalities individually and merge them using handcrafted heuristics. Such approaches work well for simple scenes, but fail to achieve high performance for speakers with large appearance variations. In this paper, we propose a novel convolutional neural networks (CNN) based learning framework to automatically learn the fusion function of both face and audio cues. We show that without using face tracking, facial landmark localization or subtitle/transcript, our system with robust multimodal feature extraction is able to achieve state-of-the-art speaker naming performance evaluated on two diverse TV series. The dataset and implementation of our algorithm are publicly available online.
- dataset
- source code
-
bibtex
@inproceedings{hu2015deep, title={{Deep Multimodal Speaker Naming}}, author={Hu, Yongtao and Ren, Jimmy SJ. and Dai, Jingwen and Yuan, Chang and Xu, Li and Wang, Wenping}, booktitle={Proceedings of the 23rd Annual ACM International Conference on Multimedia}, pages={1107--1110}, year={2015}, organization={ACM} } - DOI

Content-Aware Video2Comics with Manga-Style Layout
Guangmei Jing, Yongtao Hu, Yanwen Guo, Yizhou Yu, and Wenping Wang
IEEE Transactions on Multimedia (TMM 2015)
"auto-convert conversational videos into comics with manga-style layout"
Guangmei Jing, Yongtao Hu, Yanwen Guo, Yizhou Yu, and Wenping Wang
IEEE Transactions on Multimedia (TMM 2015)
"auto-convert conversational videos into comics with manga-style layout"
- project page
- paper
-
abstract
We introduce in this paper a new approach that conveniently converts conversational videos into comics with manga-style layout. With our approach, the manga-style layout of a comic page is achieved in a content-driven manner, and the main components, including panels and word balloons, that constitute a visually pleasing comic page are intelligently organized. Our approach extracts key frames on speakers by using a speaker detection technique such that word balloons can be placed near the corresponding speakers. We qualitatively measure the information contained in a comic page. With the initial layout automatically determined, the final comic page is obtained by maximizing such a measure and optimizing the parameters relating to the optimal display of comics. An efficient Markov chain Monte Carlo sampling algorithm is designed for the optimization. Our user study demonstrates that users much prefer our manga-style comics to purely Western style comics. Extensive experiments and comparisons against previous work also verify the effectiveness of our approach.
-
bibtex
@article{jing2015content, title={{Content-Aware Video2Comics with Manga-Style Layout}}, author={Jing, Guangmei and Hu, Yongtao and Guo, Yanwen and Yu, Yizhou and Wang, Wenping}, journal={IEEE Transactions on Multimedia (TMM)}, volume={17}, number={12}, pages={2122--2133}, year={2015}, publisher={IEEE} } - DOI
2014

Speaker-Following Video Subtitles
Yongtao Hu, Jan Kautz, Yizhou Yu, and Wenping Wang
ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM 2014)
"auto-generate speaker-following subtitles to enhance video viewing experience"
Yongtao Hu, Jan Kautz, Yizhou Yu, and Wenping Wang
ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM 2014)
"auto-generate speaker-following subtitles to enhance video viewing experience"
- project page
- arXiv (with color)
- paper
-
abstract
We propose a new method for improving the presentation of subtitles in video (e.g. TV and movies). With conventional subtitles, the viewer has to constantly look away from the main viewing area to read the subtitles at the bottom of the screen, which disrupts the viewing experience and causes unnecessary eyestrain. Our method places on-screen subtitles next to the respective speakers to allow the viewer to follow the visual content while simultaneously reading the subtitles. We use novel identification algorithms to detect the speakers based on audio and visual information. Then the placement of the subtitles is determined using global optimization. A comprehensive usability study indicated that our subtitle placement method outperformed both conventional fixed-position subtitling and another previous dynamic subtitling method in terms of enhancing the overall viewing experience and reducing eyestrain.
-
bibtex
@article{hu2014speaker, title={{Speaker-Following Video Subtitles}}, author={Hu, Yongtao and Kautz, Jan and Yu, Yizhou and Wang, Wenping}, journal={ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)}, volume={11}, number={2}, pages={32:1--32:17}, year={2014}, publisher={ACM} } - DOI
Dissertations

Multimodal Speaker Localization and Identification for Video Processing
Ph.D. Thesis, The University of Hong Kong, December 2014
"a more-or-less summary of the works published at TOMM'14, TMM'15 and MM'15"
Ph.D. Thesis, The University of Hong Kong, December 2014
"a more-or-less summary of the works published at TOMM'14, TMM'15 and MM'15"
- paper
-
abstract
With the rapid growth of the multimedia data, especially for videos, the ability to better and time-efficiently understand them is becoming increasingly important. For videos, speakers, which are normally what our eyes are focused on, have played a key role to understand the content. With the detailed information of the speakers like their positions and identities, many high-level video processing/analysis tasks, such as semantic indexing, retrieval summarization. Recently, some multimedia content providers, such as Amazon/IMDb and Google Play, had the ability to provide additional cast and characters information for movies and TV series during playback, which can be achieved via a combination of face tracking, automatic identification and crowd sourcing. The main topics includes speaker localization, speaker identification, speech recognition, etc.
This thesis first investigates the problem of speaker localization. A new algorithm for effectively detecting and localizing speakers based on multimodal visual and audio information is presented. We introduce four new features for speaker detection and localization, including lip motion, center contribution, length consistency and audio-visual synchrony, and combine them in a cascade model. Experiments on several movies and TV series indicate that, all together, they improve the speaker detection and localization accuracy by 7.5%--20.5%. Based on the locations of speakers, an efficient optimization algorithm for determining appropriate locations to place subtitles is proposed. This further enables us to develop an automatic end-to-end system for subtitle placement for TV series and movies.
The second part of this thesis studies the speaker identification problem in videos. We propose a novel convolutional neural networks (CNN) based learning framework to automatically learn the fusion function of both faces and audio cues. A systematic multimodal dataset with face and audio samples collected from the real-life videos is created. The high variation of the samples in the dataset, including pose, illumination, facial expression, accessory, occlusion, image quality, scene and aging, wonderfully approximates the realistic scenarios and allows us to fully explore the potential of our method in practical applications. Extensive experiments on our new multi-modal dataset show that our method achieves state-of-the-art performance (over 90%) in speaker naming task without using face/person tracking, facial landmark localization or subtitle/transcript, thus making it suitable for real-life applications.
The speaker-oriented techniques presented in this thesis have lots of applications for video processing. Through extensive experimental results on multiple real-life videos including TV series, movies and online video clips, we demonstrate the ability to extend our previous multimodal speaker localization and speaker identification algorithms in video processing tasks. Particularly, three main categories of applications are introduced, including (1) combine applying our speaker-following video subtitles and speaker naming work to enhance video viewing experience, where a comprehensive usability study with 219 users verifies that our subtitle placement method outperformed both conventional fixed-position subtitling and another previous dynamic subtitling method in terms of enhancing the overall viewing experience and reducing eyestrain; (2) automatically convert a video sequence into comics based on our speaker localization algorithms; and (3) extend our speaker naming work to handle real-life video summarization tasks. -
bibtex
@phdthesis{hu2014thesis, title={{Multimodal Speaker Localization and Identification for Video Processing}}, author={Hu, Yongtao}, year={2014}, month={12}, school={The University of Hong Kong} } - DOI

A New Image Blending Method based on Poisson Editing
B.S. Thesis (in Chinese), Shandong University, March 2010
"image blending via combining GrabCut and Poisson"
B.S. Thesis (in Chinese), Shandong University, March 2010
"image blending via combining GrabCut and Poisson"
- paper
-
abstract
An image is said to be worth thousands of words. However, in reality, people are not always satisfied with existed images. That’s why image blending comes to its life. Its goal is first to extract target objects from source images, and then to embed them to the target image. Nowadays, there are three popular methods as follows: one is the method used in Adobe Photoshop (not yet been published); the second is to blend two images through constructing Laplacian pyramid and doing interpolation; the third is ‘Poisson Image Editing’, which has been the basis of many blending algorithms in recent years. Although ‘Poisson Image Editing’ has concise expressions and is easy to understand and compute, its biggest weakness is that it has to rely on the extracted contour by users manually. Because it needs that users can draw the contour even for some complex images, it really gives users a great deal of inconvenience.
This paper presents a new way based on ‘Poisson Image Editing’ to do image blending. Its goal is to make users free of the tedious task of manually extracting images’ contours and improve the quality of integration. This new way of image blending consists of three main processes. Firstly, I will extract the to-be blended areas or objects (areas or objects interested) from the to-be blended images. Secondly, I can obtain the exact contours of the to-be blended areas or objects based on the first step. Thirdly, I will apply Poisson blending to do image blending based on the exact contours of the to-be blended areas or objects. The core of this new way of image blending is still Poisson blending, so it itself has the advantage of handling illumination changes between images which is the immanent advantage of Poisson blending. What’s more, and what is important is that, doing GrabCut and getting the exact contours first overcome the bad results of the blending boundary areas, because in traditional Poisson blending, the blending contours are too big. This in all makes the new way of image blending can better handle texture or color differences and produce preferable pleased results. -
bibtex
@phdthesis{hu2010thesis, title={{A New Image Blending Method based on Poisson Editing}}, author={Hu, Yongtao}, year={2010}, month={3}, school={Shandong University}, type={Bachelor's Thesis} }
Side Projects

New Methodology and Software for Improving Subtitle Presentation in Movies and Videos
07/2014 - 12/2015
ITSP project (Project Reference : ITS/226/13) with 1.4M HKD funding.
Sponsor: The Hong Kong Society for the Deaf (HKSFD).
07/2014 - 12/2015
ITSP project (Project Reference : ITS/226/13) with 1.4M HKD funding.
Sponsor: The Hong Kong Society for the Deaf (HKSFD).
- project page
-
project summary
Subtitles provide valuable aids for understanding conversational speeches in movies and videos. However, the traditional way of placing subtitles at the bottom of the video screen causes eyestrain for ordinary viewers because of the need to constantly move the eyeballs back and forth to follow the speaker expression and the subtitle. The traditional subtitle is also inadequate for people with hearing impairment to understand conversional dialogues in videos. A new technology will be developed in this project that improves upon the traditional subtitle presentation in movies and videos. In this improved presentation, subtitles associated with different speakers in a video will be placed right next to the associated speakers, so viewers can better understand what is spoken without having to move the eyeballs too much between the speaker and the subtitle, thus greatly reducing eyestrain. Furthermore, with the aid of the improved subtitle, viewers with hearing impairment can clearly associate the speaker with the spoken contents, therefore enhancing their video viewing experience. We shall apply advanced computer vision techniques to face detection and lip motion detection to identify speakers in a video scene. We shall also study the optimal placement of subtitles around an identified speaker. Finally, a prototype software system will be developed that takes a subtitled video in a standard format and produces a new video with the improved subtitle presentation. As indicated by our initial user study, the outcome of this project holds the promise of benefitting all the people viewing a subtitled video and in particular those with hearing difficulty.
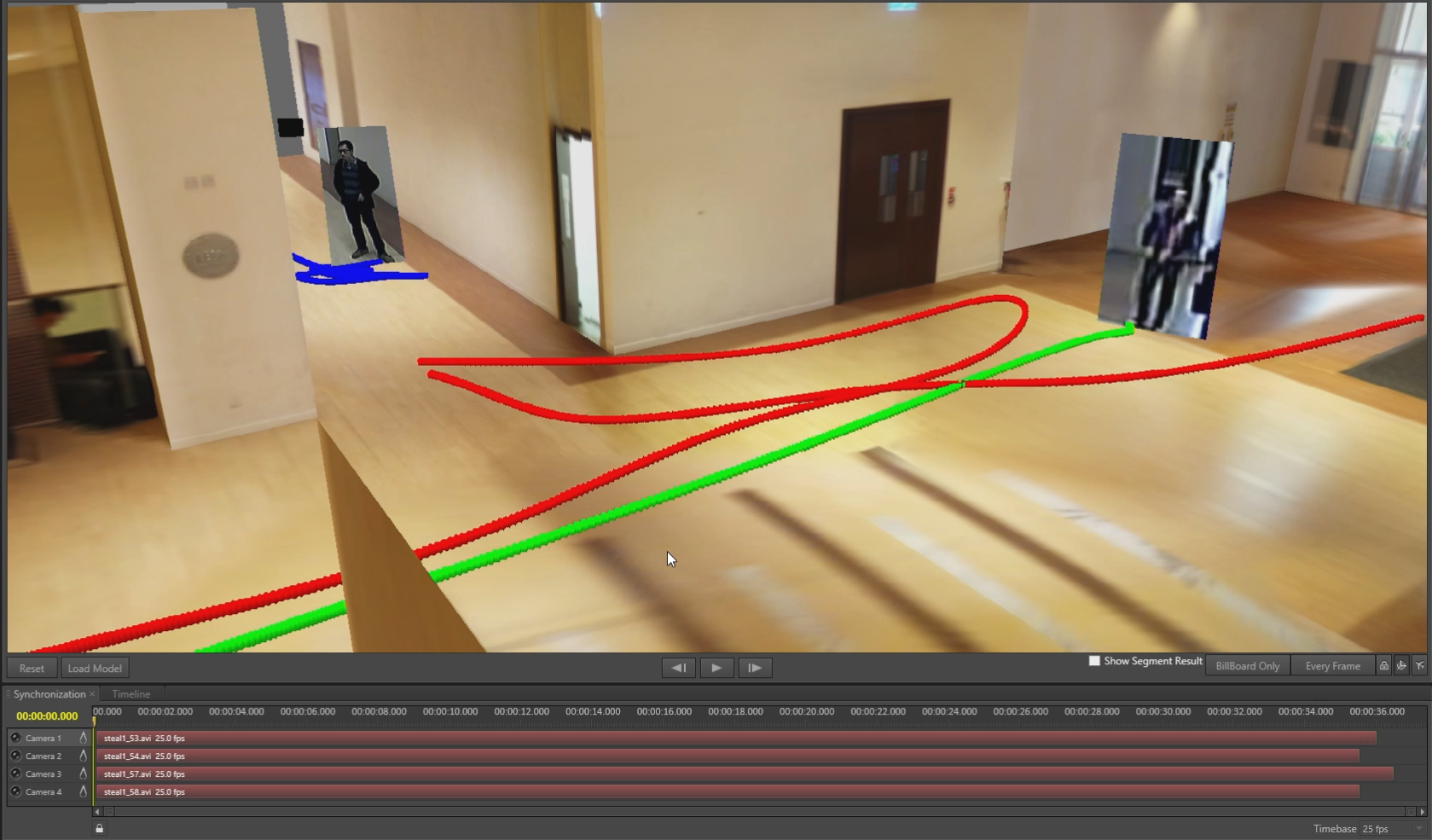
An Advanced Video Fusion System for Security Investigations
06/2012 - 09/2014
ITSP project (Project Reference : GHP/060/11) with 5M HKD funding.
Sponsors: Microsoft HK and Cyberview.
06/2012 - 09/2014
ITSP project (Project Reference : GHP/060/11) with 5M HKD funding.
Sponsors: Microsoft HK and Cyberview.
- project page
-
project summary
Video surveillance is deployed everywhere in HK to enhance public security. Security investigation is still much relied on checking 2D videos from separate camera views. This project aims at analyzing and fusing videos from multiple cameras to create an informative and easy-to-comprehend reenactment of a past event to assist investigations, providing a global understanding with both space and time registration for complex scenarios and enabling investigators to have a close-up check of actions from novel viewing directions.
- media

3D Infrared Building Modeling
03/2011 - 06/2011
Work with HKU-ME.
"3D simulation for visualizing infrared information of buildings"
03/2011 - 06/2011
Work with HKU-ME.
"3D simulation for visualizing infrared information of buildings"
- video demo #1
- video demo #2
-
project summary
A system for modeling 3D infrared building of real scenes.
Issued Patents
US Patents

- 11248911: Method and Device for Aligning Coordinate of Position Device with Coordinate of IMU, granted on Feb. 15, 2022
- 11127156: Method of Device Tracking, Terminal Device, and Storage Medium, granted on Sep. 21, 2021
- 11113849: Method of Controlling Virtual Content, Terminal Device and Computer Readable Medium, granted on Sep. 7, 2021
- 10977869: Interactive Method and Augmented Reality System, granted on Apr. 13, 2021
- 10922846: Method, Device and System for Identifying Light Spot, granted on Feb. 16, 2021
- 10916020: Method and Device for Identifying Light Source, granted on Feb. 9, 2021
- 10915750: Method and Device for Searching Stripe Set, granted on Feb. 9, 2021
- 10895799: Method and Device for Identifying Flashing Light Source, granted on Jan. 19, 2021
- 10795456: Method, Device and Terminal for Determining Effectiveness of Stripe Set, granted on Oct. 6, 2020
- 10402988: Image Processing Apparatuses and Methods, granted on Sep. 3, 2019
- 10347002: Electronic Tracking Device, Electronic Tracking System and Electronic Tracking Method, granted on Jul. 9, 2019
- 10319100: Methods, Devices, and Systems for Identifying and Tracking an Object with Multiple Cameras, granted on Jun. 11, 2019
CN Patents

- 114240981: Marking Recognition Method and Device, granted on Jun. 6, 2025
- 114549285: Controller Positioning Method, Device, Head-Mounted Display Device and Storage Medium, granted on Jun. 3, 2025
- 114545629: Augmented Reality Device, Information Display Method and Device, granted on Jan. 14, 2025
- 115100649: Method and Device for Generating Marking Pattern, Electronic Equipment and Storage Medium, granted on Jan. 7, 2025
- 113885700: Remote Assistance Method and Device, granted on Sep. 24, 2024
- 115097997: Method and Device for Deploying Mark Patterns, Electronic Equipment and Storage Medium, granted on Jul. 26, 2024
- 308706566: Display Screen Panel with Graphical User Interface for Equipment Status Monitoring, granted on Jun. 28, 2024
- 308429623: Display Screen Panel with Graphical User Interface Showing Application Software Icons, granted on Jan. 19, 2024
- 110688018: Virtual Picture Control Method and Device, Terminal Equipment and Storage Medium, granted on Dec. 19, 2023
- 110688002: Virtual Content Adjusting Method, Device, Terminal Equipment and Storage Medium, granted on Dec. 19, 2023
- 109920004: Image Processing Method, Device, Calibration Object Combination, Terminal Equipment and Calibration System, granted on Dec. 19, 2023
- 109920003: Camera Calibration Detection Method, Device and Equipment, granted on Sep. 15, 2023
- 111103969: Information Identification Method, Information Identification Device, Electronic Equipment and Computer Readable Storage Medium, granted on Sep. 1, 2023
- 111651031: Virtual Content Display Method and Device, Terminal Equipment and Storage Medium, granted on Aug. 29, 2023
- 111176445: Interactive Device Identification Method, Terminal Equipment and Readable Storage Medium, granted on Jul. 14, 2023
- 110120100: Image Processing Method, Device and Identification Tracking System, granted on Jul. 14, 2023
- 110120060: Identification Method and Device for Marker and Identification Tracking System, granted on Jul. 14, 2023
- 110120062: Image Processing Method and Device, granted on Jul. 7, 2023
- 110442235: Positioning Tracking Method, Device, Terminal Equipment and Computer Readable Storage Medium, granted on May. 23, 2023
- 111489376: Method, Device, Terminal Equipment and Storage Medium for Tracking Interaction Equipment, granted on May. 16, 2023
- 109872368: Image Processing Method, Device and Test System, granted on May. 16, 2023
- 110325872: Method and Device for Identifying Flicker Light Source, granted on Apr. 28, 2023
- 110866940: Virtual Picture Control Method and Device, Terminal Equipment and Storage Medium, granted on Mar. 10, 2023
- 110717554: Image Recognition Method, Electronic Device, and Storage Medium, granted on Feb. 28, 2023
- 110598605: Positioning Method, Positioning Device, Terminal Equipment and Storage Medium, granted on Nov. 22, 2022
- 110826376: Marker Identification Method and Device, Terminal Equipment and Storage Medium, granted on Aug. 12, 2022
- 110659587: Marker, Marker Identification Method & Device, Terminal Device and Storage Medium, granted on Aug. 12, 2022
- 111086518: Display Method and Device, Vehicle-Mounted Head-Up Display Equipment and Storage Medium, granted on May. 31, 2022
- 108701365: Light Spot Identification Method, Device and System, granted on May. 31, 2022
- 109478237: Light Source Identification Method and Device, granted on Feb. 22, 2022
- 110443853: Calibration Method and Device Based on Binocular Camera, Terminal Equipment and Storage Medium, granted on Jan. 28, 2022
- 111399631: Virtual Content Display Method and Device, Terminal Equipment and Storage Medium, granted on Nov. 5, 2021
- 111258520: Display Method, Display Device, Terminal Equipment and Storage Medium, granted on Sep. 14, 2021
- 108701363: Method, Apparatus and System for Identifying and Tracking Objects Using Multiple Cameras, granted on Jun. 29, 2021
- 110794955: Positioning Tracking Method, Device, Terminal Equipment and Computer Readable Storage Medium, granted on Jun. 8, 2021
- 110737414: Interactive Display Method, Device, Terminal Equipment and Storage Medium, granted on May. 11, 2021
- 107111882: Stripe Set Searching Method, Device and System, granted on Jan. 5, 2021
- 107223265: Stripe Set Searching Method, Device and System, granted on Nov. 27, 2020
- 211293893: Marker and Interactive Device, granted on Aug. 18, 2020
- 209591427: Marker and Interactive Device, granted on Nov. 5, 2019
- 106303161: A Kind of Image Processing Method and Electronic Equipment, granted on Jun. 25, 2019
- 208722146: Wearable Device for Auxiliary Positioning Tracking, granted on Apr. 9, 2019
- 105117495: A Kind of Image Processing Method and Electronic Equipment, granted on Dec. 14, 2018
- 107102735: A Kind of Alignment Schemes and Alignment Means, granted on Jun. 19, 2018